摘要:本文主要介紹 Presto 如何更好的利用 Hudi 的數(shù)據(jù)布局、索引信息來加速點(diǎn)查性能 。本文分享自華為云社區(qū)《華為云基于 Apache Hudi 極致查詢優(yōu)化的探索實(shí)踐!》,作者:FI_mengtao 。
背景湖倉一體(LakeHouse)是一種新的開放式架構(gòu),它結(jié)合了數(shù)據(jù)湖和數(shù)據(jù)倉庫的最佳元素,是當(dāng)下大數(shù)據(jù)領(lǐng)域的重要發(fā)展方向 。
華為云早在2020年就開始著手相關(guān)技術(shù)的預(yù)研,并落地在華為云 FusionInsight MRS智能數(shù)據(jù)湖解決方案中 。
目前主流的三大數(shù)據(jù)湖組件 Apache Hudi、Iceberg、Delta各有優(yōu)點(diǎn),業(yè)界也在不斷探索選擇適合自己的方案 。
華為湖倉一體架構(gòu)核心基座是 Apache Hudi,所有入湖數(shù)據(jù)都通過 Apache Hudi 承載,對(duì)外通過 HetuEngine(Presto增強(qiáng)版)引擎承擔(dān)一站式SQL分析角色,因此如何更好的結(jié)合 Presto 和 Hudi 使其查詢效率接近專業(yè)的分布式數(shù)倉意義重大 。查詢性能優(yōu)化是個(gè)很大的課題,包括索引、數(shù)據(jù)布局、預(yù)聚合、統(tǒng)計(jì)信息、引擎 Runtime優(yōu)化等等 。本文主要介紹 Presto 如何更好的利用 Hudi 的數(shù)據(jù)布局、索引信息來加速點(diǎn)查性能 。預(yù)聚合和統(tǒng)計(jì)信息我們將在后續(xù)分享 。
數(shù)據(jù)布局優(yōu)化大數(shù)據(jù)分析的點(diǎn)查場(chǎng)景一般都會(huì)帶有過濾條件,對(duì)于這種類型查詢,如果目標(biāo)結(jié)果集很小,理論上我們可以通過一定手段在讀取表數(shù)據(jù)時(shí)大量跳過不相干數(shù)據(jù),只讀取很小的數(shù)據(jù)集,進(jìn)而顯著的提升查詢效率 。我們可以把上述技術(shù)稱之為 DataSkipping 。
好的數(shù)據(jù)布局可以使相關(guān)數(shù)據(jù)更加緊湊(當(dāng)然小文件問題也一并處理掉了)是實(shí)現(xiàn) DataSkipping的關(guān)鍵一步 。日常工作中合理設(shè)置分區(qū)字段、數(shù)據(jù)排序都屬于數(shù)據(jù)布局優(yōu)化 。當(dāng)前主流的查詢引擎 Presto/Spark 都可以對(duì)Parquet文件做 Rowgroup 級(jí)別過濾,最新版本甚至支持 Page 級(jí)別的過濾;選取合適的數(shù)據(jù)布局方式可以使引擎在讀取上述文件可以利用列的統(tǒng)計(jì)信息輕易過濾掉大量 Rowgroup/Page,進(jìn)而減少IO 。
那么是不是 DataSkipping僅僅依賴數(shù)據(jù)布局就好了?其實(shí)不然 。上述過濾還是要打開表里每一個(gè)文件才能完成過濾,因此過濾效果有限,數(shù)據(jù)布局優(yōu)化配合 FileSkipping才能更好的發(fā)揮效果 。
當(dāng)我們完成數(shù)據(jù)布局后,對(duì)每個(gè)文件的相關(guān)列收集統(tǒng)計(jì)信息,下圖給個(gè)簡(jiǎn)單的示例,數(shù)據(jù)經(jīng)過排序后寫入表中生成三個(gè)文件,指定點(diǎn)查 where a < 10 下圖可以清楚的看出 a < 10的結(jié)果集只存在于 parquet1文件中,parquet2/parquet3 中 a 的最小值都比10大,顯然不可能存在結(jié)果集,所以直接裁剪掉 parquet2和 parquet3即可 。

文章插圖
這就是一個(gè)簡(jiǎn)單 FileSkipping,F(xiàn)ileSkipping的目的在于盡最大可能裁剪掉不需要的文件,減少掃描IO,實(shí)現(xiàn) FileSkipping有很多種方式,例如
min-max統(tǒng)計(jì)信息過濾、BloomFilter、Bitmap、二級(jí)索引等等,每種方式都各有優(yōu)缺點(diǎn),其中 min-max 統(tǒng)計(jì)信息過濾最為常見,也是 Hudi/Iceberg/DeltaLake 默認(rèn)提供的實(shí)現(xiàn)方式 。
Apache Hudi核心能力ClusteringHudi早在 0.7.0 版本就已經(jīng)提供了 Clustering 優(yōu)化數(shù)據(jù)布局,0.10.0 版本隨著 Z-Order/Hilbert高階聚類算法加入,Hudi的數(shù)據(jù)布局優(yōu)化日趨強(qiáng)大,Hudi 當(dāng)前提供以下三種不同的聚類方式,針對(duì)不同的點(diǎn)查場(chǎng)景,可以根據(jù)具體的過濾條件選擇不同的策略
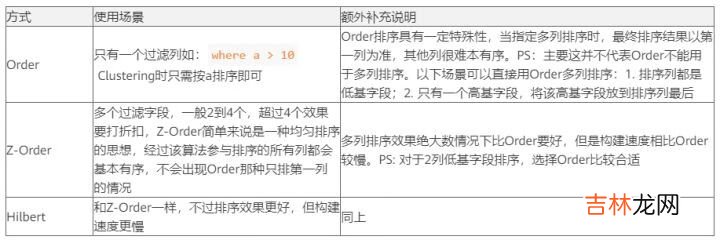
文章插圖
關(guān)于 Z-Order、Hilbert 具體原理可以查閱相關(guān)Wiki,https://en.wikipedia.org/wiki/Z-order 本文不再詳細(xì)贅述 。
Metadata Table(MDT)Metadata Table(MDT):Hudi的元數(shù)據(jù)信息表,是一個(gè)自管理的 Hudi MoR表,位于 Hudi 表的 .hoodie目錄,開啟后用戶無感知 。同樣的 Hudi 很早就支持 MDT,經(jīng)過不斷迭代 0.12版本 MDT 已經(jīng)成熟,當(dāng)前 MDT 表已經(jīng)具備如下能力
經(jīng)驗(yàn)總結(jié)擴(kuò)展閱讀
















- 14 基于SqlSugar的開發(fā)框架循序漸進(jìn)介紹-- 基于Vue3+TypeScript的全局對(duì)象的注入和使用
- 【Python+C#】手把手搭建基于Hugging Face模型的離線翻譯系統(tǒng),并通過C#代碼進(jìn)行訪問
- 基于Qt Designer和PyQt5的桌面軟件開發(fā)--環(huán)境搭建和入門例子
- 域名的由來
- www服務(wù)基于什么協(xié)議
- 背叛這個(gè)詞 被背叛了,我們應(yīng)該基于這幾個(gè)原則性問題,做出自己的抉擇
- 什么是g大調(diào) g大調(diào)是什么
- 微博是干什么用的
- 超級(jí)sim卡是什么意思
- 越是長(zhǎng)大 很多男人對(duì)一個(gè)女人的了解,那都只會(huì)基于表面,并不會(huì)有太多