企業數據越存越多,存儲容量與查詢性能、以及存儲成本之間的矛盾對于技術團隊來說是個普遍難題 。這個難題在 Elasticsearch 與 ClickHouse 這兩個場景中尤為突出,為了應對不同熱度數據對查詢性能的要求,這兩個組件在架構設計上就有一些將數據進行分層的策略 。
同時,在存儲介質方面,隨著云計算的發展,對象存儲以低廉的價格和彈性伸縮的空間獲得了企業的青睞 。越來越多的企業將溫、冷數據遷移至對象存儲 。但如果將索引、分析組件直接對接至對象存儲時會發生查詢性能、兼容性等問題 。
這篇文章將為大家介紹這兩個場景中冷熱數據分層的基本原理,以及如何通過使用 JuiceFS 來應對在對象存儲上存在的問題 。
01- Elasticsearch 數據分層結構詳解在介紹 ES 如何實現冷熱數據分層策略之前先來了解三個相關的概念:Data Stream,Index Lifecycle Management 和 Node Role 。
Data StreamData Stream(數據流)是 ES 中一個重要概念,它有如下特征:
- 流式寫入:它是一個流式寫入的數據集,而不是一個固定大小的集合;
- 僅追加寫:它是用追加寫的方式將數據更新進去,且不需要修改歷史數據;
- 時間戳:每一條新增的數據都會有一個時間戳記錄是什么時候產生的;
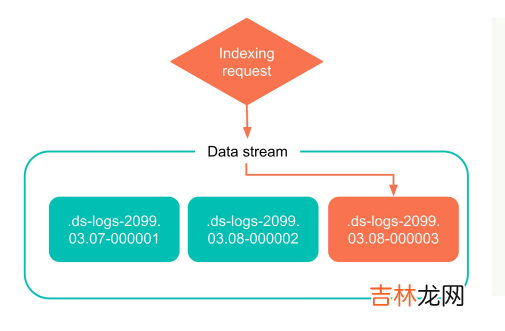
- 多個索引:在 ES 里有一個索引的概念,每一條數據最終會落到它對應的一個索引中,但是數據流是一個更上層、更大的概念,一個數據流背后可能會有很多索引,這些索引是根據不同的規則來生成的 。一個數據流雖然由很多的索引來構成,但是只有最新的索引才是可寫的,歷史索引是只讀的,一旦固化好之后就不能再修改 。
下圖是一個數據流建立索引的簡單示例,在用數據流的過程中,ES 會直接寫到最新的索引,而不是歷史索引,歷史索引不會被修改 。隨著后續更多新的數據生成,這個索引也會沉淀成為一個老的索引 。
文章插圖
下圖,當用戶往 ES 里面去寫數據時,大致分為兩個階段:
- 階段 1:數據會先寫到內存的 In-memory buffer 緩沖區;
- 階段 2:緩沖區根據一定的規則和時間,再落到本地磁盤上,就是下圖綠色的持久化的數據,在 ES 中叫做 Segment 。

文章插圖
Index Lifecycle ManagementIndex Lifecycle Management,簡稱 ILM,就是索引的生命周期管理 。ILM 將索引的生命周期定義為 5 個階段:
- 熱數據(Hot):需要頻繁更新或者查詢的數據;
- 溫數據(Warm):不再更新,但仍會被頻繁查詢的數據;
- 冷數據(Cold):不再更新,且查詢頻率較低的數據;
- 極冷數據(Frozen):不再更新,且幾乎不會被查詢的數據 。可以比較放心地把這類數據放在一個相對最低速最便宜的存儲介質中;
- 刪除數據(Delete) : 不再需要用到,可以放心刪除的數據 。
Node Role在 ES 中,每一個部署節點都會有一個 Node Role,也就是節點角色 。每一個 ES 節點會分配不同的角色,比如 master、data、ingest 等 。用戶可以結合節點角色,以及上文提到的不同生命周期的階段來組合進行數據管理 。
經驗總結擴展閱讀






- 花園蚊子多有什么辦法
- 2023年10月21日打官司行嗎 2023年10月21日適合打官司嗎
- 2023年10月21日進貨行嗎 2023年10月21日進貨好嗎
- 合歡花花語
- 華為怎么在手機桌面上創建文件夾
- 嘀嗒出租車怎么注冊
- 拯救者Y7000P獨顯模式和混合模式對比
- 爬蚱幾點到幾點最多
- 小腹胖是什么原因
- 鎖芯一般在哪里有賣